
Analysts Spend Four Hours on a Transcript and Still Miss It. This Agent Takes Five Seconds.
A technical breakdown of the Earnings Call Intelligence Agent — built on n8n, Groq, and the Mycroft Framework.

You are an analyst. It is 7:00 AM the morning after earnings. Your inbox holds seventeen calls from portfolio managers. Somewhere in a 14,000-word transcript — a document that reads like a corporate liturgy, dense with forward-looking statements and carefully rehearsed optimism — is the signal you need. Whether guidance was quietly lowered. Whether an analyst pressed on margin compression and got a non-answer. Whether a new risk was admitted in the third paragraph of the CFO’s prepared remarks, buried beneath three sentences of boilerplate reassurance.
You will spend four hours reading. You will probably miss it anyway.
That four-hour read — and everything it misses — is what the Earnings Call Intelligence Agent was designed to replace.
The Problem With Earnings Calls
Earnings calls are among the most information-dense — and information-obscured — events in corporate finance. A single transcript from a major company routinely exceeds 10,000 words. The important signals are not labeled. Management doesn’t announce, “We are quietly retreating from our full-year revenue target.” They say something like: “We remain committed to delivering value for shareholders as we navigate a dynamic macro environment.” What changed is buried inside what stayed the same.
The gap between what was said and what it means is where analysis lives. And for decades, that gap has been closed by human labor — experienced analysts who’ve read hundreds of transcripts, who know what deflection sounds like, who notice when a CEO stops using a specific phrase he used last quarter.
Scale that to a portfolio of twenty companies. To a sector analyst covering forty. To a research desk running during earnings season, when seventeen companies report in a single week.
The math doesn’t work. The signals get missed.
What the Agent Actually Does
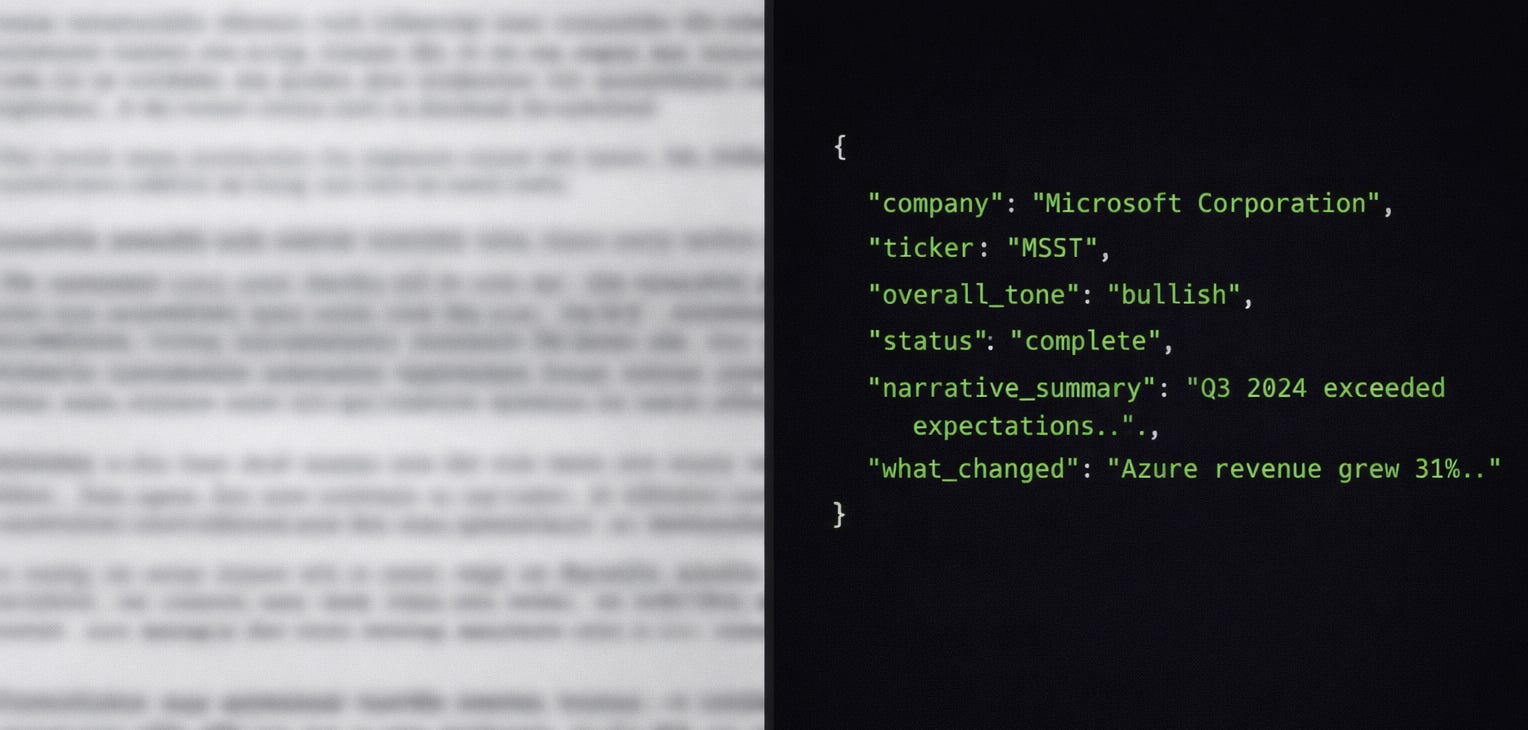
Here’s the plain-English version: POST a raw transcript. Within five seconds, the agent returns structured financial intelligence — overall tone, what changed this quarter, what didn’t, and a full map of every analyst question and how management responded. That’s the entire interface. No infrastructure to configure beyond n8n and a Groq API key, both free.
The Earnings Call Intelligence Agent is an n8n workflow — modular, open-source, and built under the Mycroft Framework, an initiative of Humanitarians.AI focused on transparent and reproducible AI tools for research and education. The architecture behind that five-second return is sequential and deliberate.
The transcript enters as raw text. A large language model — Llama-3.3-70b running on Groq — first parses it into labeled sections: CEO prepared remarks, CFO prepared remarks, Q&A exchange. Each section then routes through specialized extraction pipelines. Prepared remarks are analyzed for guidance signals and risk admissions. The Q&A section is mapped for analyst pressure, topic by topic, with a pressure score assigned to each exchange on a scale of one to ten.
Every extracted signal is stored in a seven-table PostgreSQL schema. Not archived — stored, queryable, comparable. The guidance signals table classifies each forward-looking statement as strengthened, weakened, unchanged, new, or retracted. So when a CEO shifts from “we expect strong Q3 performance” to “we remain cautiously optimistic,” the agent classifies that as weakened — it doesn’t paraphrase it away. The risk admissions table captures severity scoring and flags uncertainty language. The Q&A pressure map records what analysts pushed on, how hard they pushed, and how management responded — whether they answered directly, deflected, or pivoted to a different topic entirely.
When the pipeline completes, a final summary model synthesizes across all signals: overall tone classification, what changed this quarter, what didn’t, what the market should watch. Tested against real transcripts for Apple and Microsoft, the output is a structured JSON response that a human analyst can interrogate in minutes rather than hours.
Demo: The n8n-based Earnings Call Intelligence Agent parsing a full earnings transcript and generating structured intelligence output
The Architecture of Attention
Consider what this means at scale. A single analyst running this agent during earnings season can process twenty transcripts in the time it previously took to read three. The comparative queries are the real power: which companies in a sector weakened guidance this quarter? Which management teams have raised pressure scores on margin questions for three consecutive calls? Which risks are being admitted for the first time?
The agent doesn’t answer these questions by reading faster. It answers them by changing what gets stored.
“The agent doesn’t answer these questions by reading faster. It answers them by changing what gets stored.”
A human analyst reading a transcript takes notes that live in a document, inaccessible to comparison. The agent writes every signal to a database where the next query is a SQL statement away.
This is the architectural shift the tool represents — not faster reading, but structured memory. The transcript stops being a document you read once and set aside. It becomes a row in a dataset that grows richer every quarter.
The Mycroft Framework’s transparency principle means the audit trail is built in. Every claim in the database is tied to an exact quote from the transcript. If the guidance signal classification seems wrong, the source text is there to review. The agent does not paraphrase management and then lose the original language. It stores both.
What the Agent Cannot Do
The limitations are worth leading with, because this is where most AI tooling goes dishonest.
Guidance signal extraction is rated medium accuracy, dependent on transcript length and specificity. Precise metric values — exact revenue figures, margin percentages stated in passing during Q&A — are classified medium-low, most reliably extracted when explicitly stated by the speaker rather than implied. Q&A pressure scoring is directionally correct but subjective; a score of seven means something different depending on the analyst asking and the company being pressed.
The project documentation states plainly: this tool is best used for directional signal detection rather than precise number extraction, and for comparative analysis across many calls where individual errors average out. It is designed as a first-pass intelligence layer that a human analyst then reviews — not as a replacement for that review.
This framing matters. The temptation with any AI extraction system is to treat its outputs as authoritative. The agent resists that temptation structurally — by rating its own accuracy by signal type, by tying every claim to a source quote, by being explicit that Q&A pressure scores are assessments, not measurements.
The Larger Stakes
Earnings calls sit at the intersection of corporate disclosure law, investor psychology, and the management of narrative at the highest organizational levels. Companies are legally required to disclose material information. They are strategically incentivized to disclose it in ways that minimize immediate market impact. The tension between those two facts produces the specific genre of language that earnings calls have become — carefully hedged, forward-looking-statement-prefaced, and calibrated by teams of lawyers and investor relations professionals.
The analyst’s job — and now the agent’s job — is to read through that calibration: to find what changed inside the language designed to make change invisible.
The agent will not catch everything. The LLM misses subtle hedging, buries guidance changes that live in single sentences, and cannot model the specific pressure history between a company and its most skeptical analysts. But it catches more than any single human reading at scale, stores what it catches in a form that compounds over time, and does so transparently enough that its misses can be identified and corrected.
That last point — transparency about failure modes — is what separates this from the AI tools that promise to solve analysis entirely. The Earnings Call Intelligence Agent doesn’t promise the oracle. It promises a better first read.
The transcript still requires interpretation. The signal still requires judgment. What changes is how much of the analyst’s attention is spent finding the signal in the first place — and how much is left for the work only a human can do.
Try It Yourself
The workflow JSON and PostgreSQL schema are available on GitHub — no infrastructure required beyond n8n and a free Groq API key. To test it immediately, open Postman, POST your transcript as JSON to the webhook URL, and you'll see the full structured response in under five seconds. If you’re testing it against your own transcripts, running it on a sector you cover, or building on top of the architecture, I’d like to hear what you find.
Drop a comment below with what you tested it on, or reply directly to this email. And if this kind of work — open-source AI tools built for financial research and education — is what you’re here for, subscribe to stay current as the project develops.
Project Resources:
GitHub : [ Link ]
Video : [ Link ]
Built under the Mycroft Framework by Humanitarians.AI. The author is affiliated with this initiative — disclosed in the interest of transparency.